

Introduction
In multicloud environments, while using resources from multiple cloud vendors, you usually deal with migrating data across the environments or keeping it on one cloud environment while accessing it from another. The Oracle Database DBMS_CLOUD PL/SQL package allows you to access data on OCI Object Storage, Azure Blob Storage, and Amazon S3 buckets or import it into an Oracle Database from these sources.
This blog post provides a step-by-step guide on accessing and importing data from Amazon S3 into an Oracle Database.
The Environment
- Data files in an AWS S3 bucket.
- Oracle Autonomous Database on OCI, as DBMS_CLOUD package is already pre-installed. You can use any Oracle Database version 19.10 and higher where you can install the DBMS_CLOUD package.
For testing purposes, network connectivity is established over the internet. For production environments, set up a private dedicate connection between AWS and OCI via a 3rd party network service provider.
Preparation on AWS
Step 1: Grant your AWS IAM user access privileges to S3 bucket
From the IAM page, choose Users in the Access management section, and click on the group assigned to the user:

Choose the Permissions tab and add a policy that allows access to the S3 bucket where your data is stored, for example:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": "s3:*",
"Resource": "*"
}
]
}
You can restrict the access further to only specific resources.
Step 2: Create an Access Key for your AWS IAM user
From the IAM page, choose Users in the Access management section, and click on the user name. Choose the Security credentials tab and click on Create access key:

You will be prompted to download a .csv file that contains your Access Key ID and Secret Access Key. For example:
Access key ID: AKIA2PCQOXHEFKTB6SU2
Secret access key: 7MymZxpyL3NDJeNpMrfuDE8FJ1fp70BNpsP2Le9b
We will use these later in step 4.
Step 3: Get your AWS S3 object URL
Get the URL of the object (the data file) stored in an S3 bucket that you want to import into an Oracle Database. From the Amazon S3 page, choose Buckets, and click on the bucket name where your objects reside. Click on the object name and copy the Object URL:
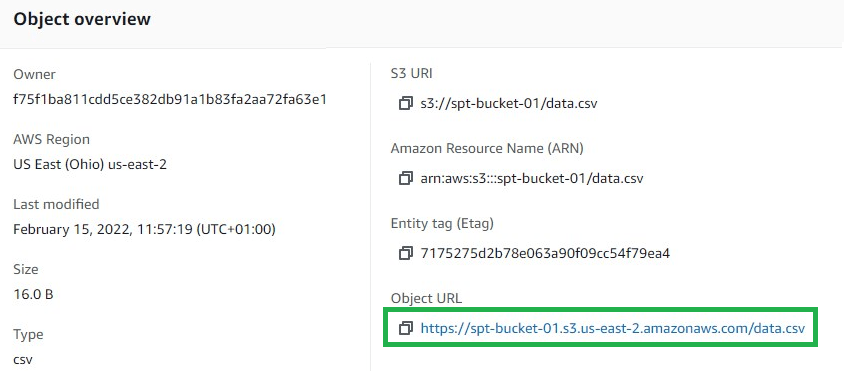
In this case, the data.csv file is elementary and contains two rows only with data separated by a comma:
1,name1
2,name2
Preparation on OCI
Step 4: Create the credentials in the Oracle Database
Create the credentials using the DBMS_CLOUD PL/SQL package to allow the database to access the S3 objects. Use the Access Key from step 2:
BEGIN
DBMS_CLOUD.CREATE_CREDENTIAL(
credential_name => '<Crednedial_Name>',
username => '<Access_Key_ID>',
password => '<Secret_Access_Key>'
);
END;
/
-- for examplae
SQL> BEGIN
DBMS_CLOUD.CREATE_CREDENTIAL(
credential_name => 'AWSCRED',
username => 'AKIA2PCQOXHEFKTB6SU2',
password => '7MymZxpyL3NDJeNpMrfuDE8FJ1fp70BNpsP2Le9b'
);
END;
/
PL/SQL procedure successfully completed.
Step 5: Test the access to S3 bucket
To test the access to the S3 bucket, list the files using the LIST_OBJECTS function of the DBMS_CLOUD package. Use the credential name from step 4 and the location URL from step 3; however, without the object name at the end:
SQL> select * from dbms_cloud.list_objects('AWSCRED', 'https://spt-bucket-01.s3.us-east-2.amazonaws.com/');
OBJECT_NAME BYTES CHECKSUM CREATED LAST_MODIFIED
_________________ _________ ___________________________________ __________ ______________________________________
data.csv 16 7175275d2b78e063a90f09cc54f79ea4 15-FEB-22 10.57.19.000000000 AM GMT
data.txt 16 11b315d6a7d39e72b11f9440c48bca1c 15-FEB-22 10.46.41.000000000 AM GMT
sampleuser.dmp 356352 044d1699939defe97836c478e1ed1059 15-FEB-22 12.18.26.000000000 PM GMT
Importing Data
Step 6: Import data from S3 bucket to Oracle Database
Now we are ready to import the data using the COPY_DATA procedure of the DBMS_CLOUD package.
Import from .csv file:
SQL> create table mydata (id number, name VARCHAR2(64));
Table MYDATA created.
SQL> BEGIN
DBMS_CLOUD.COPY_DATA(
table_name => 'mydata',
credential_name => 'AWSCRED',
file_uri_list => 'https://spt-bucket-01.s3.us-east-2.amazonaws.com/data.csv',
format => json_object('delimiter' value ',')
);
END;
/
PL/SQL procedure successfully completed.
SQL> select * from mydata;
ID NAME
_____ ________
1 name1
2 name2
Import from .txt file:
BEGIN
DBMS_CLOUD.COPY_DATA(
table_name => 'mydata',
credential_name => 'AWSCRED',
file_uri_list => 'https://spt-bucket-01.s3.us-east-2.amazonaws.com/data.txt',
format => json_object('delimiter' value ',')
);
END;
/
Oracle Data Pump import:
# data pump parameter file: imps3.par
directory=DATA_PUMP_DIR
credential=AWSCRED
schemas=sampleuser
remap_tablespace=USERS:DATA
dumpfile=https://spt-bucket-01.s3.us-east-2.amazonaws.com/sampleuser.dmp
# data pump import command
impdp userid=ADMIN@adbfra_high parfile=imps3.par
External Tables
If you want to keep your files on S3 while accessing the data through an Oracle Database, you can create an external table pointing to the files on S3 using the CREATE_EXTERNAL_TABLE procedure of the DBMS_CLOUD package:
SQL> BEGIN
DBMS_CLOUD.CREATE_EXTERNAL_TABLE(
table_name => 'exttab',
credential_name => 'AWSCRED',
file_uri_list => 'https://spt-bucket-01.s3.us-east-2.amazonaws.com/data.csv',
column_list => 'id NUMBER, name VARCHAR2(64)',
format => json_object('delimiter' value ',')
);
END;
/
PL/SQL procedure successfully completed.
SQL> select * from exttab;
ID NAME
_____ ________
1 name1
2 name2
Conclusion
The DBMS_CLOUD package provides the flexibility to access data on multiple cloud vendors and a simple way to import it into an Oracle Database, simplifying data migrations across clouds.
Further Reading
- 10 Reasons to Adopt a Multicloud Strategy
- Considerations and Challenges of Multicloud and how to Overcome them
- AWS RDS for Oracle to Autonomous Database using Zero Downtime Migration
- Import your Data directly from Object Storage in Oracle Database 21.3 and 19.12
- Save Storage Cost with Hybrid Partitioned Tables in Oracle Autonomous Database
- What should I consider when migrating to Autonomous Database using Data Pump?
