

One of the most beneficial cloud features is scalability on-demand, paying only for what you use, and releasing the resources when not needed anymore. So the question is, could I configure the standby database to use fewer CPUs than the primary to save costs?
Yes, BUT… you have to consider a few things!
Oracle Cloud provides an automated way to set up a Data Guard configuration by the click of a button. For example, for DBCS VM, choose a smaller shape on the “Enable Data Guard” page when you initiate the process. Keep in mind that the shape you choose also determines the network bandwidth and IOPS you get.

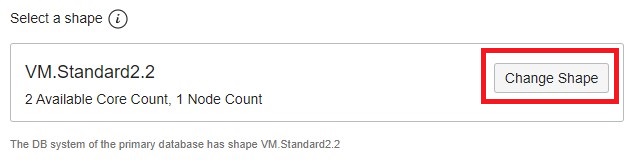
For DBCS Bare Metal or ExaCS, you would just enable fewer OCPUs on the standby side. Anyway, you’d have to consider the following:
Workload on Primary and Standby
Every transaction on the primary is replayed on standby. Your standby database (even if only in the mounted state) should be able to handle the workload coming from the primary. If this is not the case, and you run in SYNC mode, you’d encounter a delay in transaction commits on the primary. In the case of ASYNC, the lag between primary and standby could get bigger because the redo apply performance is too slow on the standby side.
If you are using Active Data Guard, consider the additional workload resulting from the Read-Only statements on standby.
Switchover
Before switchover, you’d need to make sure that the current standby runs with more resources now. This is not critical, as it does not affect the availability of the primary. For DBCS VMs, changing the shape is an offline operation, so the primary is not protected during the “change shape” process. But I think you could live with that in most cases.

Failover
The failover case is more critical. Here, you’ll need to scale up the primary database. In the case of DBCS Bare Metal or ExaCS, scaling up is an online operation, but you still have to think about doing it.
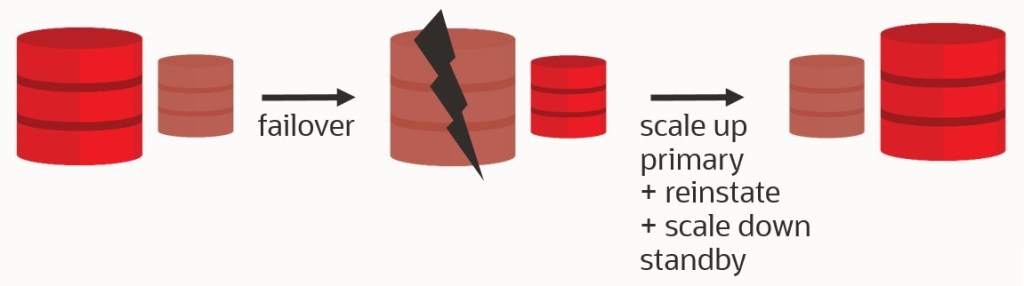
However, changing the shape of a DBCS VM requires downtime, which would count to your RTO. Also, do you want to do such an operation on your primary while your standby (the older primary) is actually broken?
If you are using RAC, then the change shape operation takes place in a rolling fashion, allowing you to change the shape with no database downtime.
Conclusion
Assign enough resources to your standby to handle the traffic coming from the primary. For DBCS Bare Metal or ExaCS scaling up and down is an online operation and is done easily. Changing the shape of a virtual machine requires downtime that you might not have after a failover. Using RAC eliminates the downtime needed for the change shape operation.
In the end, Disaster Recovery is about ensuring high availability and saving your data, not saving money.
